Beyond-Factoid-QA-Effective-Methods-for-Non-factoid-Answer-Sentence-Retrieval
Sentence Retrieval for Non-factoid QA by Liu Yang for ECIR2016
Abstract
- Task: Retrieving finer grained text units such as passages or sentences as answers for non-factoid Web queries.
- Challenge: The difference between Non-factoid QA and Factoid QA.
This Work:
- Design two types of features, namely semantic and context features.
- Compare learning to rank methods with multiple baseline methods including query likelihood and the state-of-the-art convolutional neural network based method.
Evaluation: Results show that features used previously to retrieve topical sentences and factoid answer sentences are not sufficient for retrieving answer sentences for non-factoid queries, but with semantic and context features, we can significantly outperform the baseline methods.
Research Questions
- Could we directly apply existing methods like factoid QA methods and sentence selection methods to solve this task?
- How could we design more effective methods for answer sentence retrieval for non-factoid Web queries?
Contributions
- We formally introduce the answer sentence retrieval task for non-factoid Web queries, and build a benchmark data set (WebAP) using the TREC GOV2 collection.
- Based on the analysis of theWebAP data, we design effective new features including semantic and context features for non-factoid answer sentence retrieval.
- The results show that MART with semantic and context features can significantly outperform existing methods including language models, a state-of-the-art CNN based factoid QA method and a sentence selection method using multiple features.
Related Work
- Answer Passage Retrieval
- Answer Retrieval with Translation Models
- Answer Ranking in CQA
- Answer Retrieval for Factoid Questions
Task Definition
We now give a formal definition of our task.
- non-factoid questions: ${Q_1,Q_2, \cdots, Q_n}$
- Web documents: ${D_1,D_2,\cdots, D_m}$ that may contain answers
- our task is to learn a \alert{ranking model} $R$ to rank the sentences in the Web documents to find sentences that are part of answers. The ranker is trained based on available \alert{features} $F_S$ and \alert{labels} $L_S$ to optimize a \alert{metric} $E$ over the sentence rank list.
Our task is different from previous research in the TREC QA track and answer retrieval in CQA sites likeYahoo! Answers.
- Answers could be much longer than in factoid QA
- The search space is much larger than CQA answer posts.
Dataset
- Then we map “Perfect”, “Excellent”, “Good”, “Fair” to 4-1 and assign 0 for all the other sentences.
- There are 991233 sentences in the data set and the average length of sentences is 17.58.
- After label propagation from passage level to sentence level, 99.02\% (981510) sentences are labeled as 0 and less than 1\% sentences have positive labels (149 sentences are labeled as 1; 783 sentences are labeled as 2; 4283 sentences are labeled as 3; 4508 sentences are labeled as 4.)

Baseline Experiments
- Retrieval functions: query likelihood language model with Dirichlet smoothing (LM).
- Factoid question answering method: CNN
- Summary sentence selection method: MART
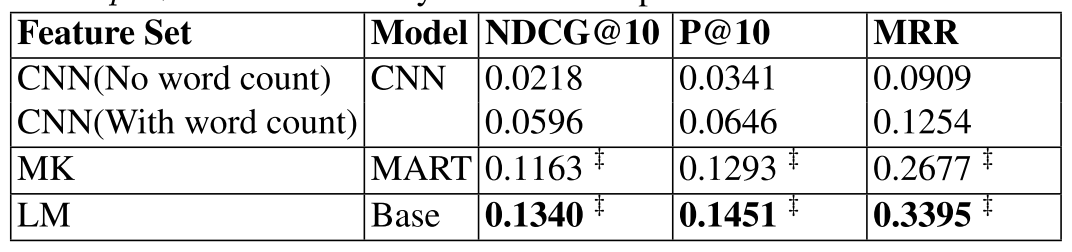
This result shows that automatically learned word features (as in CNN) and simple combined text matching features (as in MK) may not be sufficient for our task, suggesting that a newset of techniques is needed for non-factoid answer sentence retrieval.
Capturing Semantics and Context
http://rmit-ir.github.io/SummaryRank\\
MK features:
- ExactMatch: a binary feature indicating whether the query is a substring of the sentence.
- TermOverlap: measures the number of terms that are both in the query and the sentence after stopping and stemming.
- SynonymsOverlap. the fraction of query terms that have a synonym in the sentence, computed by using Wordnet.
- SentLength
- SentLocation
LM feature:\
LanguageModelScore. $$f_{LM}(Q,S)=\sum_{w\in Q}tf_{w,Q}log\frac{tf_{w,S}+\mu P(w|C)}{|S|+\mu}$$
Semantics Features
- ESA: Explicit Semantic Analysis is a method that represents text as a weighted mixture of a predetermined set of natural concepts defined byWikipedia articles which can be easily explained. Semantic relatedness is computed as the cosine similarity between the query ESA vector and the sentence ESA vector.
- WordEmbedding: Word embeddings are continuous vector representations of words learned from large amount of text data using neural networks. We compute this feature as the average pairwise cosine similarity between any query-word vector and any sentence-word vector.
- EntityLinking: Linking short texts to a knowledge base to obtain the most related concepts gives an informative semantic representation that can be used to represent queries and sentences.(entity linking system Tagme) The Jaccard similarity is the semantic feature.$$TagmeOverlap(q,s)=\frac{Tagme(q) \cap Tagme(s)}{Tagme(q) \cup Tagme(s)}$$
Context Features
Context features are features specific to the context of the candidate sentence.
- SentenceBefore: MK features and semantic features of the sentence be- fore the candidate sentence.
- SentenceAfter: MK features and semantic features of the sentence after the candidate sentence.
Learning Models
- MART(http://www.lemurproject.org/ranklib.php): Multiple Additive Regression Trees
- LambdaMART(https://code.google.com/p/jforests/) combines the strengths of MART and LambdaRank which has been shown to be empirically optimal for a widely used information retrieval measure.
- Coordinate Ascent(http://www.lemurproject.org/ranklib.php) is a list-wise linear feature-based model for information retrieval which uses coordinate ascent to optimize themodel’s parameters.
Results

Examples
