RNN(Recurrent Neural Network)
RNN的简介,数学原理,代码实现 by Guoxiu for starting learning
声明
本文参照了Understanding LSTM Networks和The Unreasonable Effectiveness of Recurrent Neural Networks
想深入学习的同学,建议阅读以上两个博客或者相关论文。
简介
- RNN可以对序列中前一个输入对当前输入的影响进行建模
- 传统的神经网络模型中,是从输入层到隐藏层再到输出层,曾与层之间是全连接的,每层之间的节点是无连接的。而RNN会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的。
- RNN天生适合语言模型
- 基于RNN的seq2seq和attention机制在文本表达上取得了极大的进展
- RNN已经被广泛的应用于语音识别、语言模型、翻译和图像检测。
原理
标准RNN原理
- RNN(Recurrent Neural Network):They are networks with loops in them, allowing information to persist.
图示如下: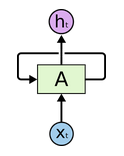
其中$x_t$是输入,$A$是中间的隐藏层,$h_t$是输出。循环允许把隐藏层的信息从第一个step传递到下一个step,这个同人类的记忆类似。其实一个RNN可以看作是好几个相同网络的复制,把上图展开如下所示: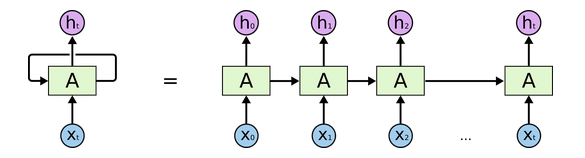
解释如下:在每一个step中,不仅接受当前step的输入,还接受上一个step的隐藏层作为输入。
更细节的展示: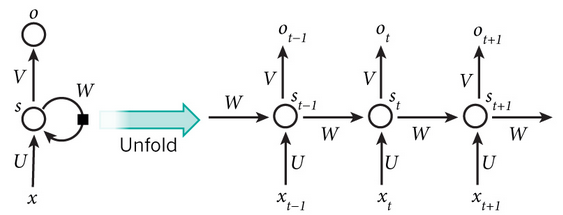
其中,$x$是输入,$s$是隐藏层,$o$是输出,$t$是step,$U$是输入到隐藏层的权重,$W$是前一个隐藏层到当前隐藏层的权重,$V$隐藏层到输出的权重。在每个step中,对应的输入序列$x$被输入,然后更新共同的参数(有效的降低了需要学习的参数):$U$,$W$,$V$。计算隐藏层的公式为:$s_t=f(Ux_t+Ws_{(t-1)})$,其中$f$为tanh或者ReLU。计算输出的公式为:$o_t=softmax(Vs_t)$,是当前step的输出。 - Long-Term依赖的问题
语言模型是在先前单词的基础之上,预测下一个单词。RNN是如何做到递归操作,能够把之前的信息连接到当前的任务?
在处理短依赖时,如下图所示: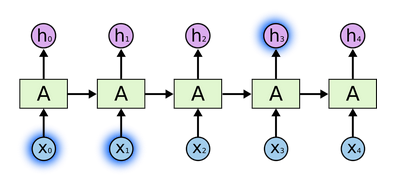
在处理长依赖时,如下图所示: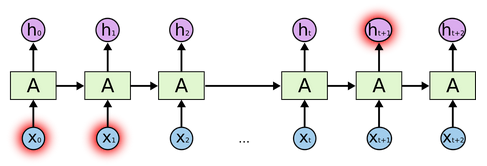
之前的信息都被存放在隐藏层$A$中。在理论上,RNN可以解决这种长项依赖的问题。但是在实际中,RNN不能学到这些内容。所以LSTM(Long Short Term Memory networks)被提出以解决这些问题。 - 之前神经网络模型的限制:
只接受一个固定的向量作为输入(如一个图片),产生一个固定的向量作为输出(如不同类别的概率)。不仅如此,这些模型有固定的计算步骤(如网络有固定的层数) - RNN的核心特征:
允许用户操作向量的序列:输入序列,输出序列或者在大多数情况下都可以操作。 - 常见RNN模型对比,如下图所示
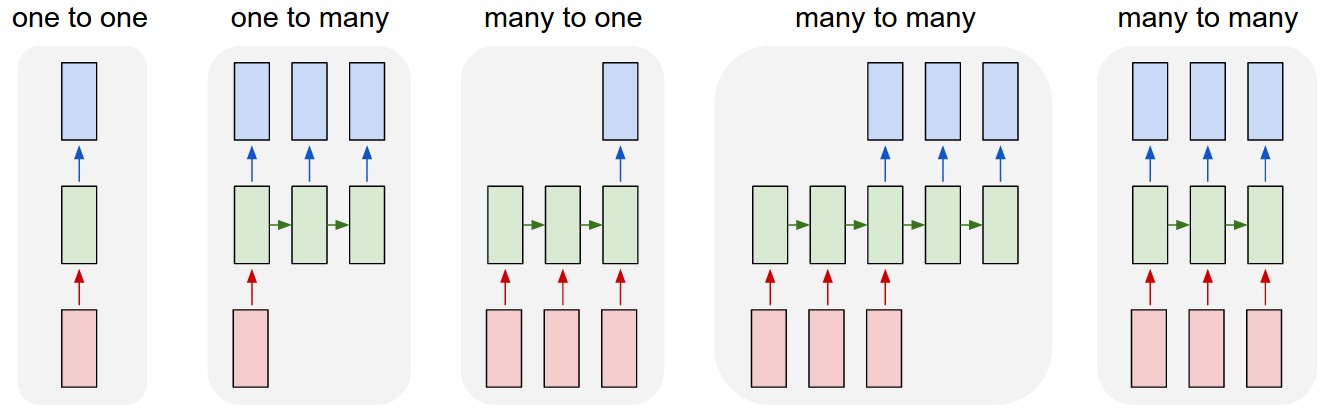
- 解释:每个矩形是一个向量,箭头是表达方法(如矩阵相乘)。红色的矩阵是输入向量,蓝色的矩阵是输出向量,绿色的矩阵是隐藏层向量。
- 第一:Vanilla模型区别于RNN的是输入一个固定的向量,输出一个固定的向量(如图像分类)。
- 第二:输入一个固定的向量,输出一个序列(如输入一个图片,输出一个文字序列)。
- 第三:输入一个序列,输出一个固定的向量(感情分析任务为输入一个文字序列,输出分类类别)
- 第四:输入一个序列,输出一个序列(机器翻译为,输入一个文字序列,输出一个文字序列)。
- 第五:输入一个序列,输出对应的序列(对视频的每一帧进行标注)。
LSTM原理
- LSTM是为了解决RNN无法有效实现长项依赖而设计的。
- 所有的RNN都是一个不停的重复相同模型(自己)链。在标准的RNN里,计算隐藏层的模型非常简单,只有一个tanh层。如下图所示:
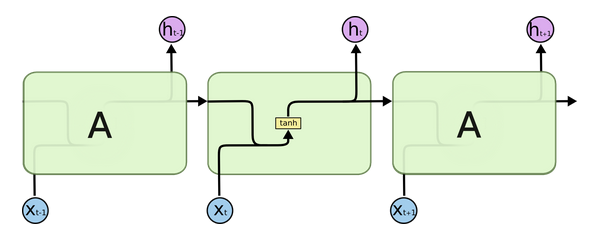
可以发现,这个结构非常简单,当前的输入和上一层的隐藏层仅仅用tanh进行激活。具体如上所示。 - 和标准RNN一样,LSTM也是类似这样的一个重复结构,但是隐藏层的计算有很大的不同。如下所示:
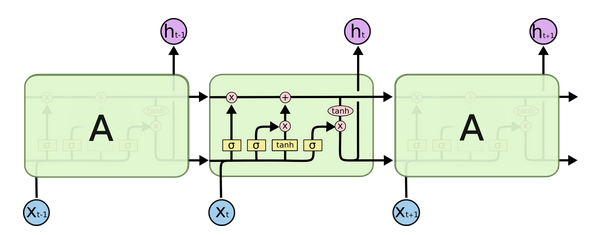
首先熟悉一下图例:
从左到右依次是:神经网络层(有激活函数操作),逐点操作,向量移动方向,向量合并,向量复制。 - LSTM的核心思想就是在隐藏层加入了门以控制数据流。它就像一个信息的传送带,在整个链中,只携带一些线性操作来增加信息。最简单的情况就是,整个过程中,通过门控,什么都没有改变。如下图所示:
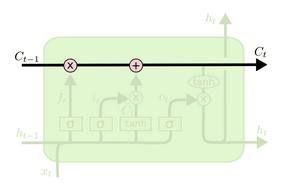
门控使得LSTM有能力增加或者移除隐藏层中的信息。门控的图示如下: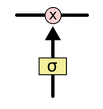
sigmoid层的输出数介于0~1之间,0表示没有信息可以通过,1表示允许所有信息通过。
LSTM有三个门。每一步如何计算如下所示: - 第一步:”forget gate layer”——决定什么信息要被丢弃。
$f_t=\sigma(W_f\cdot[h_{t-1}, x_t]+b_f)$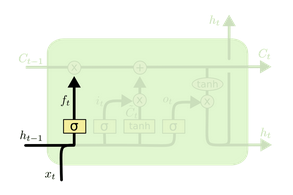
- 第二步:”input gate layer”——决定什么信息要被添加。
$i_t=\sigma(W_i\cdot[h_{t-1}, x_t]+b_i)$ - 第三步:”create candidate”——生成候选集合(就是标准RNN!!)。
$\hat C_t=tanh(W_C\cdot[h_{t-1}, x_t]+b_C)$ - 第四步:更新原来的隐藏层$C_{t-1}$到新的隐藏层$C_t$。通过$f_t\cdot C_{t-1}$确定要遗忘的旧的隐藏层,通过$i_t\cdot\hat C_t$确定可以更新的候选集。这样,模型选择性的丢掉了旧的信息,选择性的加上了新的信息。结果是这样的:
$C_t=f_t\cdot C_{t-1}+i_t\cdot\hat C_t$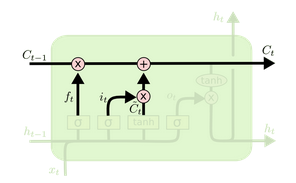
- 第五步:决定输出什么。利用sigmoid门决定tanh后的输出。
$o_t=\sigma(W_o[h_{t-1}, x_t]+b_o)$, $h_t=o_t\cdot tanh(C_t)$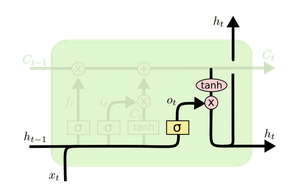
其中的核心就是利用sigmoid函数对传输的信息进行控制。更多LSTM
- 上文介绍的是最普通的LSTM,几乎每篇论文的LSTM都会有所不同。
- Gers & Schmidhuber(2000)提出的的LSTM变种,增加了”peephole connections”。把以藏层也加入了门控。如下图所示:
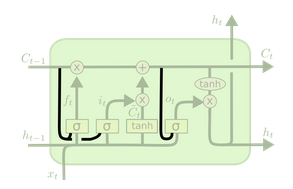
$f_t=\sigma(W_f\cdot[C_{t-1}, h_{t-1}, x_t]+b_f)$
$i_t=\sigma(W_i\cdot[C_{t-1}, h_{t-1}, x_t]+b_i)$
$o_t=\sigma(W_t\cdot[C_t, h_{t-1}, x_t]+b_o)$ - 增加了”coupled forget and input gates”,用共同考虑什么该被遗忘什么该被增加代替了原来分别考虑的问题。如下图所示:
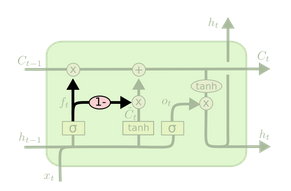
$C_t=f_t\cdot C_{t-1}+(1-f_t)\cdot\hat C_t$ - GRU(Gated Recurrent Unit) introduced by Cho, et al.在更新门中增加了遗忘和输入门,还有其他更新若干。如下图所示:
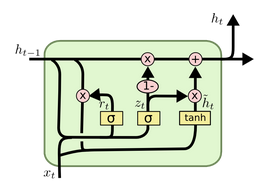
$z_t=\sigma(W_z\cdot[h_{t-1}, x_t])$
$r_t=\sigma(W_r\cdot[h_{t-1}, x_t])$
$\hat h_t=tanh(W\cdot[r_t\cdot h_{t-1}, x_t])$
$h_t=(1-z_t)\cdot h_{t-1}+z_t\cdot \hat h_t$
LSTMs were a big step in what we can accomplish with RNNs. It’s natural to wonder: is there another big step? A common opinion among researchers is: “Yes! There is a next step and it’s attention!” The idea is to let every step of an RNN pick information to look at from some larger collection of information.
代码
伪代码
RNN的特点是隐藏层不仅由当前step的输入决定,还受上一个step的隐藏层的影响。具体的伪代码如下:
1234567891011# RNN类class RNN:def step(self, x):# 更新隐藏层self.h = np.tanh(np.dot(self.W_hh, self.h) + np.dot(self.W_xh, x))# 计算输出向量y = np.dot(self.W_hy, self.h)return yrnn = RNN()# x是一个输入向量,y是一个RNN的输出向量y = rnn.step(x)解释一下:
- RNN的参数是三个矩阵,
W_hh,W_xh和W_hy。 - 隐藏层
self.h被初始化为零向量。 np.tanh是一个非线性的方法,把值激活至[-1, 1]。得到一个新的隐藏层向量:$h_t=tanh(W_{hh}h_{t-1}+W_{xh}x_{t})$- 在tanh中包括两部分:一个基于之前的隐藏层,一个基于当前的输入,分别利用
np.dot计算输入和权重的结果。tanh在元素级被应用。 - 初始时,所有参数被随机赋值。在loss函数的作用下,在给定x的情况下,输出越来越接近y。
- RNN的计算就主要理解那个代码就行:)。
- RNN的参数是三个矩阵,
深度学习:
12y1 = rnn1.step(x)y = rnn2.step(y1)解释:
我们有两个独立的RNN,第一个RNN接受输入向量,第二个RNN将第一个RNN的输出作为输入,接受输出向量。通过反向传播算法进行优化。LSTM(Long Short-Term Memory)性能比一般会好。要修改的地方就是self.h = ...
Keras代码
keras代码封装的很好,可以快速实现原型
1234567891011121314151617# 加载必要的keras代码库from keras.models import Sequentialfrom keras.layers import Dense, Dropout, Activation, Embeddingfrom keras.layers import LSTM, SimpleRNN, GRU# 新建一个模型model = Sequential()# 输入是一个sequence的每个word的embedding,具体的参数可调model.add(Embedding(max_features, 128, dropout=0.5))# RNN模型:GRU或者LSTM。封装的就是这么好model.add(GRU(256, dropout_W=0.5, dropout_U=0.5))# 用全连接接输出层,激活函数可以是sigmoid或者softmaxmodel.add(Dense(1))model.add(Activation('sigmoid'))# 还是像之前一样进行优化即可model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])keras就是这样简单粗暴。你只要处理好数据(符合规范的输入和输出),按照自己的想法搭建模型,最后调参训练即可。
Tensorflow代码
- 这个实现的也是LSTM,主要参照tensorflow提供的官方教程。普通RNN的实现就简单看看那个伪代码吧。
LSTM实现的过程如下。
12345678910111213141516171819# 新建LSTM的神经元lstm = rnn_cell.BasicLSTMCell(lstm_size)# 初始化LSTM的隐藏层(记忆)state = tf.zeros([batch_size, lstm.state_size])# 初始化概率和损失函数probabilities = []loss = 0.0# 利用batch进行模型优化for current_batch_of_words in words_in_dataset:# 在处理完这个batch的单词之后,更新隐藏层的值。LSTM接受的输入是当前输入的值和上一个隐藏层的值,输出是更新后的隐藏层的值和输出。# The value of state is updated after processing each batch of words.output, state = lstm(current_batch_of_words, state)# 之后接全连接,加softmax,然后更新loss# softmax的作用是在当前词的基础上,预测下一个词的概率# The LSTM output can be used to make next word predictionslogits = tf.matmul(output, softmax_w) + softmax_bprobabilities.append(tf.nn.softmax(logits))loss += loss_function(probabilities, target_words)具体内容还有待补充…